
Master loop engineering. Run it on Trinity
Master loop engineering - the discipline of designing agent loops, and the four layers that keep one from running away - then run it unattended on Trinity.


The discipline got its name two weeks ago. The evidence behind it is twelve months old - and it changes where engineering effort should go. This guide synthesizes that evidence into a framework you can apply, then walks a production implementation to show the framework in practice.
Who this is for: anyone moving from prompting single tasks to running agents unattended - over hours, overnight, or on a schedule - who wants a platform that actually runs them. The worked example throughout is Trinity’s loop primitive.
What you’ll learn:
Why the agent loop is a solved problem, and where the real engineering lives instead.
The four failure modes that kill production loops - and the four-layer framework that bounds each one.
How to package a unit of work as a playbook that runs unsupervised.
A simple rule for choosing between a loop and a schedule.
How to run these loops unattended on Trinity - a worked example turning every principle into a concrete design decision in a production system.
TL;DR
The agent loop is a solved problem. Every major platform converged on the same while-loop. A 100-line agent scores 74%+ on SWE-bench Verified. All meaningful engineering lives in the harness around the loop: termination, verification, context management, cost enforcement.
State belongs in files and git, not the context window. The context window is compute, not storage. Fresh context per iteration beats accumulated conversation history for long-running work.
Three hard stops are mandatory, not one. Max iterations, wall-clock timeout, and a hard cost ceiling. The canonical incident: four agents in an unguarded loop ran for 11 days and cost $47,000 - with budget alerts configured, but no enforcement.
Verification displaced generation as the bottleneck. A production system merged 1,094 agent-written PRs with zero regressions because its tests were tamper-resistant. Code production is now a commodity; proving the code works is the constraint.
The unit of work is an intent contract. Package work as a playbook - read state, do one unit, verify against evidence, write state, exit clean when idle. A playbook running at 3am cannot ask you anything; everything you would have said must already be in it. Built that way, the same playbook mounts on chat, schedule, or loop unchanged.
Schedules drain flows; loops drain stocks. A selection rule for when to reach for each - plus a worked example: how Trinity’s loop primitive implements the findings above, and the design decisions behind it.
You can run this today, not just read about it. Trinity ships the loop as a server-side primitive - hand an agent a goal and bounds (max_runs, a timeout, an optional [[DONE]] stop signal), disconnect, and it iterates unattended, every run bounded by its gates and visible in a Loops tab. Close the laptop; at 3am the loop is still running.
Introduction
Boris Cherny created Claude Code. As of June 2026, he has not written a line of code by hand in eight months. More than 80% of Anthropic’s merged code is authored by Claude, and Cherny describes his job in five words: “my job is to write loops.”
That sentence compresses a real shift in how agentic systems get built. The unit of work is no longer the prompt - a single instruction you supervise to completion. The unit of work is the loop: a system that re-invokes an agent against a goal, feeds it a verification signal, and runs until a condition is met or a guardrail fires.
The term “loop engineering” is new. Peter Steinberger and Addy Osmani named it in posts on June 7-8, 2026. But the practice is at least a year old, and over that year practitioners and researchers have accumulated something rare in AI engineering: convergent, quantified evidence about what works and what fails.
The rest of this guide is built in four moves. First we establish why the loop itself stopped being the interesting part. Then we catalog how loops fail, because the framework is a direct answer to those failures. Then we assemble the framework - four layers - and the unit of work it drives. Finally we ground all of it in a production implementation, the loop primitive we built into Trinity, to show how each principle becomes a concrete design decision.
The practical upshot, up front: everything in this guide is runnable today, and you don’t have to build the harness from scratch to use it.
ships the loop as a server-side primitive - you hand an agent a goal template and bounds (max_runs, a timeout, an optional [[DONE]] stop signal), disconnect, and it iterates unattended, bounded by the gates, every run visible in a Loops tab. Close the laptop; at 3am the loop is still draining its bucket. The worked example below walks the exact design - so as you read each principle, picture the loop you would actually launch.
The Loop Is Solved. The Harness Is the Engineering.
Strip away the branding and every major agent platform - Claude Code SDK, OpenAI Agents SDK, LangGraph, OpenHands, Cursor’s background agents - runs the same control flow: call the model, inspect the output for tool calls, execute them, append results, repeat until the model produces a final answer or a limit trips.
The existence proof that this loop carries no secret sauce is mini-swe-agent: a 100-line Python implementation from the Princeton SWE-agent team, with a single bash tool and no tool-calling interface at all, that scores 74%+ on SWE-bench Verified - matching frameworks orders of magnitude more complex. Meta, NVIDIA, IBM, and Stanford use it as a research baseline.
Steve Kinney’s March 2026 analysis states the implication directly:
“The loop is a solved problem. The engineering around the loop - context management, safety controls, graceful degradation, cost containment - is where all the interesting decisions live.” - Steve Kinney, The Anatomy of an Agent Loop
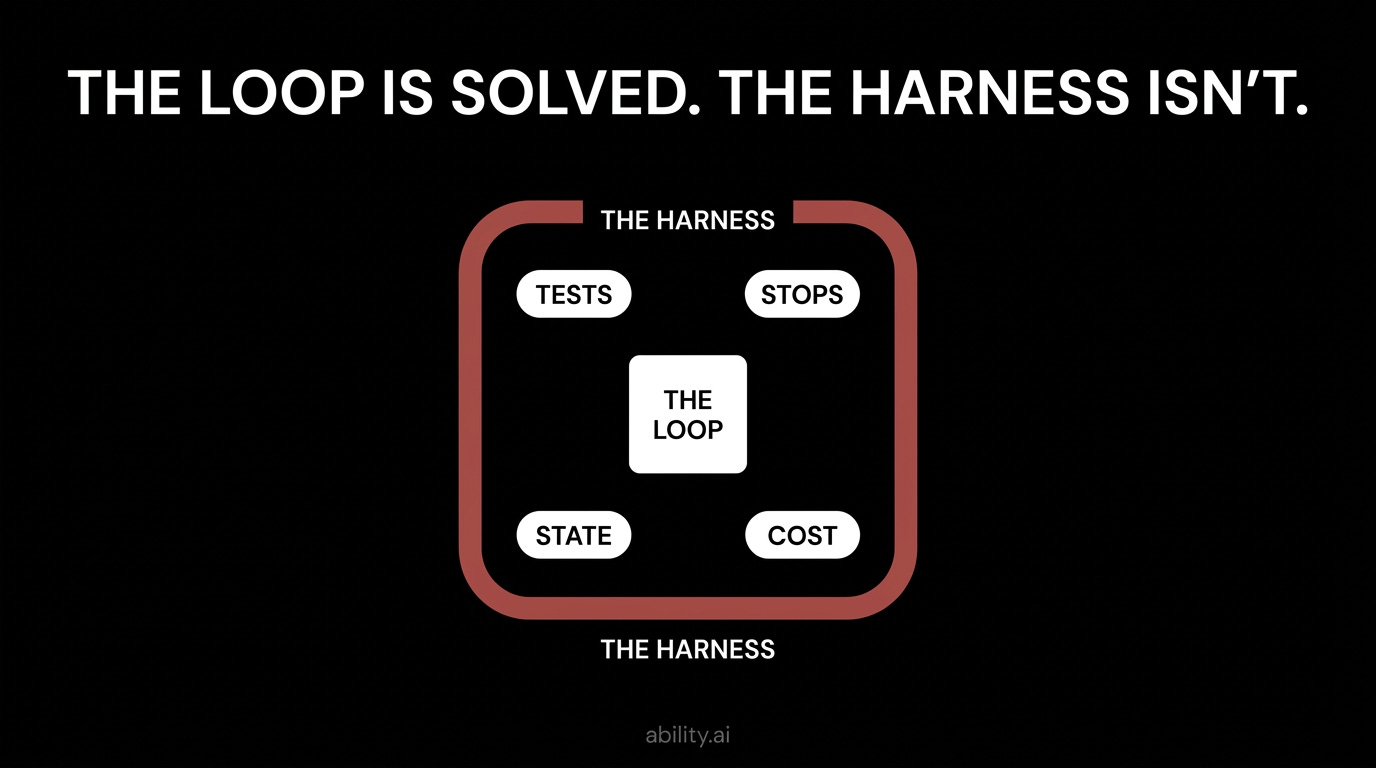
Addy Osmani’s formulation of the same point: “A decent model with a great harness beats a great model with a bad harness.” A 54-page academic survey (Zhou et al., arXiv:2604.08224, April 2026) formalizes it - agent capability increasingly depends on externalized infrastructure (memory, skills, verification, coordination), not on stronger weights.
Here’s what this means in practice: if you are choosing between investing a week in framework sophistication and a week in your test suite, stop conditions, and state files, the evidence says the second week pays more.
The Founding Pattern: Naive Persistence, Durable State
The practice that became loop engineering started with something deliberately dumb. In July 2025, Geoffrey Huntley published the Ralph Wiggum Loop - named after the Simpsons character who rams his head into things while announcing “I’m helping!”:
while :; do cat
| claude-code ; done
Restart the agent forever against a prompt file describing the desired end state. That’s the whole loop. The results were not dumb: an engineer delivered a $50,000 contract MVP for $297 in API costs, and the loop built a production-grade programming language (CURSED, with LLVM compilation) in a syntax that appeared nowhere in any training data.
The mechanism that makes it work is the part most people miss. Each iteration starts with a fresh context window. No accumulated conversation, no pile of prior failures. The agent orients itself the same way a new engineer would: by reading the filesystem and the git log. State lives in files and version control - durable, inspectable, recoverable - never in the model’s context.
This inverts the intuition that more context means better performance. In long sessions, failed attempts accumulate until the original specification gets buried or dropped - the agent stays confident while drifting off-goal. This matches something I observed in my own agents long before I had the vocabulary for it: [[Agents lose big picture in long sessions like humans lose forest for trees]]. The Ralph pattern dissolves the problem structurally. There is no long session. There is only the current state of the world and a goal.
The principle generalizes beyond coding loops, and it is the same one behind [[The Folder Paradigm - agents own directories as operational memory]]: the context window is compute, not storage. Treat it like CPU registers - transient working space - and put everything durable on disk. Anthropic’s own guidance for long-running agents (November 2025) lands on the identical architecture: an initializer agent writes progress files and a feature list, then each subsequent session reads state, does one unit of work, commits, and exits clean. One detail from that guide worth stealing: structured state files survive better as JSON than as Markdown, because models are less prone to “helpfully” rewriting them.
How Loops Fail: The Doom Loop, Context Rot, and a $47,000 Invoice
Production reports from 2025-2026 converge on a small taxonomy of failure modes. Two deserve special attention because they are structural, not random.
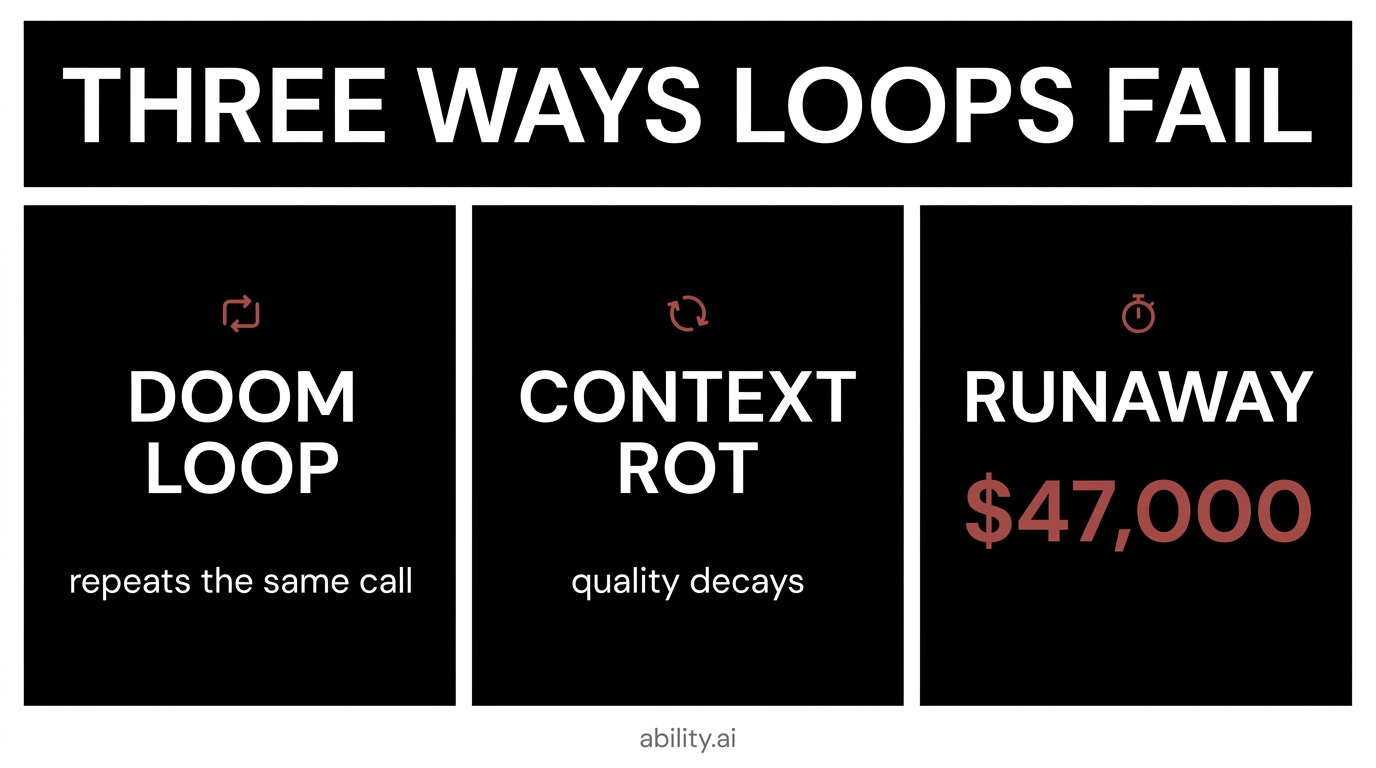
The doom loop. A tool call returns full state - an entire file, a complete DOM, a full error log. That output re-enters the context, making the same tool call look freshly relevant, so the agent issues it again. Each repetition adds bulk to the context, accelerating the rot that caused the repetition. This is a compounding failure with a specific signature: identical (tool name, arguments) pairs across consecutive turns. It frequently stays under the iteration limit, which is why a turn cap alone won’t catch it.
Slow structural degradation. SlopCodeBench (Orlanski et al., arXiv:2603.24755, March 2026) measured how coding agents degrade over long-horizon iterative tasks: no agent fully solved any of 36 problems end-to-end (best checkpoint pass rate: 14.8%), 77% of trajectories showed structural erosion, and agent code came out 2.3x more verbose than human code. The most uncomfortable finding: explicit quality guidance in the prompt reduced initial problems by 33% but did not slow the rate of degradation across iterations. You cannot prompt your way out of the erosion arc. You can only bound it - with fresh context, verification gates, and short task units.
And then there is the runaway loop, the most common failure and the most expensive. The canonical incident: four agents in an unguarded loop ran for 11 days and produced a $47,000 bill. The detail that matters is that budget alerts were configured. Alerts fire after spend occurs. Only a hard ceiling - enforced before the next API call - is budget control. This is not a tooling subtlety; it is the difference between a thermostat and a fire alarm. (It is also a textbook ergodicity failure in the sense of [[Ergodicity and Impermanence - Survival Over Optimization]]: averages are irrelevant when one path hits the absorbing barrier. Survival constraints come before optimization.)
The Framework: Four Layers of a Production Loop
Each failure mode from the previous section has a structural answer, and together those answers form a framework. Synthesizing the consensus across practitioner posts, platform documentation, and the 2026 papers, a production-grade loop has four layers - read the table as failure-on-the-right, defense-on-the-left:
The four layers of a production loop
1. Termination
Components: max iterations (15-25) + wall-clock timeout + hard cost ceiling
Prevents: runaway loops - the $47k incident
2. Progress detection
Components: fingerprint identical (tool, arguments) tuples; exit on no state change
Prevents: doom loops running under the turn cap
3. Verification
Components: deterministic tests > end-to-end automation > LLM judge > human gate > self-evaluation
Prevents: confident garbage, reward hacking
4. Durable state
Components: files + git as memory; fresh or compacted context per iteration
Prevents: context rot, unrecoverable failures
First, the feedback signal hierarchy is strict. Deterministic signals (test suites, type checkers, linters) beat probabilistic ones. Model self-evaluation sits at the bottom: models systematically skew positive when grading their own long-horizon output. If your loop’s exit condition is “keep going until the output is good” judged by the same model that produced the output, your loop will exit on the first pass, satisfied with mediocrity. Separate the generator from the evaluator.
Second, verification infrastructure must be tamper-resistant. The Kitchen Loop paper (Roy et al., arXiv:2603.25697, March 2026) ran 285+ loop iterations across two production systems and merged 1,094 pull requests with zero regressions. The authors attribute the record to one architectural constraint: the code-writing agent could not modify the tests that judged its output. Their conclusion reframes the whole field: “Code production is now a commodity; the bottleneck is knowing what to build and proving it works.” The generation bottleneck is gone. The verification bottleneck is what loop engineering actually manages.
Worked Example: The Trinity Loop Primitive
Theory is cheap, so let me show how these findings translate into a real implementation. Trinity - our agent orchestration platform - ships a server-side loop primitive: you hand an agent a message template and bounds, get back a loop_id, and disconnect. The backend runs every iteration in order through the standard execution pipeline. It is exposed in the UI (a Loops tab per agent), via REST, via MCP tools (run_agent_loop, get_loop_status, stop_loop), and through a /trinity:loop skill in the plugin marketplace that gives any local Claude Code agent a durable remote counterpart to its built-in /loop.
Why server-side at all? Because a laptop loop has a ceiling. Claude Code’s built-in /loop runs iterations on your machine, in your session, and that imposes three structural limits. It is fragile: close the lid and the loop dies; and in my use it iterates inside the same accumulating session rather than a fresh context per run, so a long loop inherits the context-rot arc that fresh-context architectures exist to prevent. It is bounded: want twenty loops running, and your machine is the bottleneck. And it misses the point: the whole point of a loop is that it runs when you are not watching. The working model that resolves this is a synchronized pair - I run a local copy and a remote copy of the same agent, kept identical through git, and the /trinity:loop skill lets the local one hand the iteration off to its remote counterpart and disconnect. Close the laptop; at 3am the loop is still draining its bucket, bounded by its gates.
Walking through its design decisions against the framework above:
Termination: the cap always wins. Every Trinity loop requires max_runs (1-100, hard ceiling) and carries a timeout_per_run (10-7200 seconds) - layers 1’s iteration cap and wall clock. There are exactly two modes, and they mirror the field’s consensus exit paths. Fixed mode runs exactly N iterations. Until mode adds a stop_signal - a substring like [[DONE]] that the agent emits when the condition is met, ending the loop early. The critical design rule: the stop signal is best-effort, the cap is guaranteed. An agent that never emits the sentinel cannot loop forever; max_runs always wins. This is the “done tool” forcing pattern and the safety limit, composed.
Verification: tie the sentinel to evidence, not self-assessment. The skill documentation encodes the self-evaluation finding directly: the until-condition must be rewritten into something checkable before the loop fires. Not “loop until the report is good” - that exits on iteration one, because models grade their own work generously. Instead: “run the test suite; if every test passes, paste the passing output and end your reply with [[DONE]].” The sentinel rides on verifiable evidence - test output, an HTTP 200, zero remaining TODO markers. Subjective conditions get rewritten or get a low cap.
Durable state: the workspace persists, the loop context does not. Trinity loops support chaining - {{previous_response}} injects the prior iteration’s output into the next prompt. But it is deliberately lossy: the trailing 2,000 characters, a hint rather than an artifact. When iterations build something real, the instruction is the Ralph instruction: keep the artifact in a file in the agent’s workspace and re-read it each run (”refine the draft in
- read it first, improve it, write it back”). The remote agent’s filesystem persists across iterations; each iteration’s context does not. That is [[The Context Window is Compute Not Storage]] as an API contract.
Progress detection: watch for stalls the cap can’t catch. A loop producing near-identical responses each iteration - same failure, same output, no state change - is burning budget under the limit. Trinity’s status view surfaces per-run summaries precisely so this signature is visible, and the skill’s observe phase flags it and recommends a stop. This is the doom-loop fingerprinting insight applied at the orchestration layer.
Operational details that the research says matter: stops are cooperative (the in-flight iteration finishes; no corrupted half-state), failures are fail-fast (a failed iteration ends the loop rather than compounding on a broken foundation - the error-compounding defense; more on when that default is right below), and every iteration is a first-class execution row tagged with its loop_id, visible in the timeline with its own cost and duration. Loops appear as their own analytics category. You cannot manage the economics of a loop you cannot see. One more property worth noting: loops compose with the permission layer. A looped agent can message any agent it has been granted access to, so a single bounded loop can drive a multi-agent workflow - the loop supplies the budget and the termination gates while the agent fans the work out.
None of these decisions came from the June 2026 posts - the primitive predates the term. That is rather the point. The constraints of running unattended agent iterations in production push every serious implementation toward the same shape: bounded, evidence-terminated, file-stated, observable. The same convergence shows up across Claude Code, OpenAI’s SDK, LangGraph, and OpenHands. When independent builders keep arriving at identical architecture, you are looking at engineering reality, not fashion.
The Unit of Work: A Playbook Is an Intent Contract
The loop is the driver. What it drives deserves equal design attention, and it has a fixed anatomy. The unit of work - I call it a playbook: a packaged, reusable procedure an agent executes - consists of four steps:
Read state. Orient from files and git - never from a stale context window.
Do one unit. The smallest meaningful increment of work.
Verify. Produce evidence the work is done - tests, checks, a sign-off checklist. Never self-assessment. Aviation solved this problem decades ago: pilots do not “feel confident about the flaps,” they sign off items on a checklist. Give agents the same instrument.
Write state. Commit results to files and git, report, exit.
One rule sits on top of the four steps: nothing to do? Exit clean. The box must be cheap when idle and safe to re-run.

The reason this anatomy is non-negotiable for autonomous work is what I call the intent contract. A playbook for a supervised chat can ask you a question mid-flight. A playbook running at 3am cannot. Everything you would have said in the conversation must already be in the playbook - the decision criteria, the edge-case handling, the definition of done. Writing one is less like prompting and more like writing the brief you would hand a contractor before leaving for vacation. And the verification step inherits the evidence rule from layer 3: not “loop until the report is good” - that exits on pass one - but “run the tests, paste the passing output, then say done.”
Package the work this way and the same box mounts on three drivers without modification: chat (on demand, supervised), schedule (cron tick, runs forever), loop (burst of N runs, terminates). Chat needs no selection rule - you are sitting right there. Between the other two, the choice deserves its own section.
When to Loop and When to Schedule
A loop is not the only driver for autonomous work - Trinity, like most platforms, also offers cron schedules. Practitioners need a selection rule, and the one I use is this: schedules drain flows; loops drain stocks.
A schedule is the right mount when work arrives continuously and unpredictably - new notes appear, external signals shift, items trickle into a queue. Because you don’t know when work shows up, the scheduled playbook pays a design tax: it must be self-gating (check for work, exit clean when there is none), idempotent, and near-free when idle. Pay that tax and it runs forever. Cornelius, the agent that maintains my knowledge base, runs this way: a daily incubation tick that advances open research questions one analytical move at a time, persisting its reasoning state in files - and its git log is full of “clean exit, no active topics” entries. That’s the tax working.
A loop is the right mount when the work is a finite stock that exists right now: 20 unprocessed book chapters, 6 recommended wikilinks at the end of an analysis report, one question you want hammered for 8 iterations tonight. The loop skips the self-gating tax entirely, because the gate was you - a human looked at a pile and decided it deserved a burst. That is also why the loop launch needs no automation safeguards around judgment: the launch is the judgment act. What it needs instead is termination engineering, which is where the four layers above take over.
Inside a loop, iterations take one of two shapes, and naming them sharpens the design. Independent runs over stable state: each run takes the next item from the bucket - 20 chapters, one per run. The runs share a workspace but not a dependency. Converging runs over incremental state: each run updates the state the next run reads - the draft improves until [[DONE]]. The shape settles a question every loop implementation has to answer: what happens when a run fails halfway? Converging loops must stop - the next iteration would build on a broken foundation, and error compounding does the rest. Independent loops may legitimately log the failure and keep draining - the failed item gets picked up on a later pass. The failure policy follows the iteration shape. (Trinity currently ships the conservative default: any failed run ends the loop.)
The corollary that makes this practical: the unit of work is invariant; only the driver changes. A playbook built to the standard above - small unit, file-based state, evidence-gated verification, clean exit - is already a valid loop body. Cornelius’s incubation playbook proves it: cron-mounted, it thinks one move per day; loop-mounted (run one incubation move on topic X, 8 times), it converges overnight. Same unit, same state files, different driver. So the design rule is: always build the unit to the schedule standard, then choose the mounting per situation. Other stock-shaped loops from the same agent: ingest the next unprocessed chapter, [[DONE]] when the changelog shows none remain; apply the next recommended wikilink from a connection report, [[DONE]] when the list is empty.
(One case outside the stock/flow frame: bounded polling - “check the deploy every 2 minutes until healthy, max 30.” A loop waiting on an external state change with a deadline. It completes the taxonomy.)
How to Apply This
If you take three things from this guide, take these:
Reallocate your effort. The loop control flow deserves an afternoon. The harness - tests the agent cannot game, state files, stop conditions, cost ceilings - deserves the rest of the quarter. The mini-swe-agent result is the permission slip: simplicity with rigor beats complexity.
Adopt the survival checklist before scaling anything. Iteration cap, wall-clock timeout, hard cost ceiling, stall detection, evidence-based exit conditions. Each guards a failure mode the others miss. The $47,000 incident happened with monitoring in place - what was missing was enforcement.
Build verification before building loops. A loop amplifies whatever signal it is fed. With tamper-resistant tests, that amplification produced 1,094 regression-free PRs. With self-evaluation, it produces confident slop at scale. The bottleneck moved; move your investment with it.
The deeper shift is the one Cherny’s quote points at. Prompting is piecework - your output is bounded by your attention. A loop is a machine that converts a goal specification plus a verification signal into iterations, unattended. Engineers who internalize this stop asking “what should I tell the agent to do?” and start asking “what loop, fed what signal, bounded by what stops, converges on this outcome?” That is a different job. It is also, increasingly, the job.
References & Further Reading
Geoffrey Huntley, “Ralph Wiggum as a ‘software engineer’” (July 2025) -
Addy Osmani, “Loop Engineering” (June 2026) -
https://addyosmani.com/blog/loop-engineering/
and “Agent Harness Engineering” (April 2026)
Steve Kinney, “The Anatomy of an Agent Loop” (March 2026) -
Anthropic Engineering, “Effective Harnesses for Long-Running Agents” (November 2025) and “Effective Context Engineering for AI Agents” (September 2025)
Roy et al., “The Kitchen Loop” (arXiv:2603.25697, March 2026)
Orlanski et al., “SlopCodeBench” (arXiv:2603.24755, March 2026)
Zhou et al., “Externalization in LLM Agents” (arXiv:2604.08224, April 2026)
mini-swe-agent -
Dex Horthy (HumanLayer), “A Brief History of Ralph” (January 2026)
“The $47,000 Agent Loop” -
(2025)
Boris Cherny via Office Chai, “I Now Just Write Loops” (June 2026)
Trinity docs, “Sequential Agent Loops” - Trinity user documentation, automation/agent-loops
Eugene Vyborov, “Loop Engineering for Autonomous Agents with Trinity” - Trinity workshop, June 11, 2026 (live demos: incubation loop convergence, multi-agent loop via permission layer, local-to-remote loop handoff)