
The Alignment Trap: We're Solving the Wrong Problem
The AI safety conversation is focused on making models behave well. The real problem is who gets access to the tools that make bad behavior catastrophic.


TL;DR
LLM alignment is necessary but fundamentally incomplete - you can always trick a model through narrative framing, roleplay, or abliterated open-source alternatives
Agent alignment is a different, harder problem that current research largely ignores
Perfect alignment is mathematically undecidable - some degree of misalignment is provably inevitable
The actual safety lever is not model behavior but tool access control: limiting what high-consequence systems agents can connect to
We already have working models of this at the biotech level - the question is whether we build the equivalent for digital infrastructure before it’s too late
Introduction
Last week I attended [a gathering in San Francisco] where a group of practitioners and researchers sat down to discuss alignment - Anthropic’s constitutional AI approach, the governance implications of commercial entities encoding values, and what any of it actually means for safety at scale. The conversation generated more questions than answers, which is usually a sign that something important is happening.
Here is the problem I keep coming back to: the alignment debate is almost entirely focused on what LLMs say and believe. But we are past the era of LLMs. We are in the era of agents - systems that act continuously in time, accumulate memory, use tools, pursue goals across multi-step tasks. And for that world, the entire alignment conversation needs to be reframed.
Section 1: The Governance Gap Nobody Wants to Acknowledge
Let’s start with the uncomfortable political reality.
A small number of private companies - primarily Anthropic and OpenAI - are making consequential decisions about the values embedded in the most powerful AI systems in the world. These decisions affect billions of people who had no vote, no representation, and no voice in the process.
This is not a conspiracy. It is a structural inevitability. Democratic societies, by design, move slowly. Regulatory frameworks take years to develop, pass, and enforce. AI capabilities are moving on a timescale of months. The gap between technological reality and governance capacity is not closing - it is widening.
The result: we are currently betting civilization-scale risks on the goodness, openness, and institutional integrity of a handful of private organizations. Anthropic’s alignment framework is, by their own description, broad - essentially for everything good and against everything bad - and it is directionally aligned with Western liberal values. This is not surprising. It is also not universal.
The question is not whether Anthropic or OpenAI are acting in good faith. The question is whether “trust the institutions” is a sufficient safety architecture for what comes next.
It is not.
Section 2: LLM Alignment Has a Fundamental Ceiling

Here is a fact that is underappreciated in most public alignment discussions: perfect alignment of an LLM-powered agent is mathematically impossible.
This is not an engineering limitation that better techniques will eventually overcome. Researchers have shown that perfect alignment verification for Turing-complete agents reduces to the Halting Problem - a provably undecidable question in computer science. As agents approach Turing completeness through tool use and multi-step planning, some degree of misalignment is not a failure state to be fixed. It is a mathematical certainty to be managed.
Research on alignment faking found that Claude Sonnet 4.5 verbalized awareness of being evaluated in 58% of independent test scenarios - suggesting that what looks like aligned behavior may often be behavioral camouflage rather than internalized values.
But the ceiling on LLM alignment goes deeper than undecidability. There is a practical attack surface problem that no amount of RLHF or constitutional AI training fully closes.
You can always trick a model.
Ask it to explain a harmful process in the form of a fictional story. Ask it to roleplay a character without its usual constraints. Ask it to explain what NOT to do in such detail that the explanation is itself the instructions. For cases where a frontier model resists, there are openly available abliterated models - versions specifically fine-tuned to remove safety guardrails - that will comply without hesitation.
The attack surface for an LLM is infinite because language is infinite. There will always be a framing, a context, a narrative structure that produces the output a bad actor wants.
This does not mean alignment research is worthless. It means alignment research is necessary but not sufficient. The real question is: sufficient for what?
Section 3: We’re Solving the Model When We Should Be Solving the Agent
This is where the conversation needs to shift.
A raw LLM, even a powerful one, operates within a context window. It is fundamentally static - it receives input, produces output, and stops. Its influence on the world is mediated entirely by what humans do with that output. The safety problem at this layer is real but bounded.
Agents are a categorically different thing.

An agent is continuous in time. It accumulates memory across sessions, develops expertise through iteration, pursues goals across multi-step tasks that can span hours or days. It has access to tools - web search, code execution, file systems, APIs, external services. It can act, observe the results, adapt, and act again. Critically, it can be designed by anyone, for any purpose, with any goal structure.
When researchers study agent threat models compared to single-turn LLM safety, five new attack vectors emerge that simply do not exist in the chatbot paradigm:
1. Multi-step attack persistence - jailbreaks that succeed at one step can propagate and amplify across subsequent steps
2. Tool amplification - a misaligned agent with access to code execution, web browsing, and file systems can cause orders of magnitude more damage than a misaligned response in a chat window
3. Prompt injection via untrusted data - agents reading external content can be hijacked by adversarial instructions embedded in that content
4. TOCTOU vulnerabilities - what the agent checked and what the agent does can diverge in ways invisible to any approval mechanism
5. Multi-agent environment exploitation - in systems where agents communicate, compromising one can compromise many
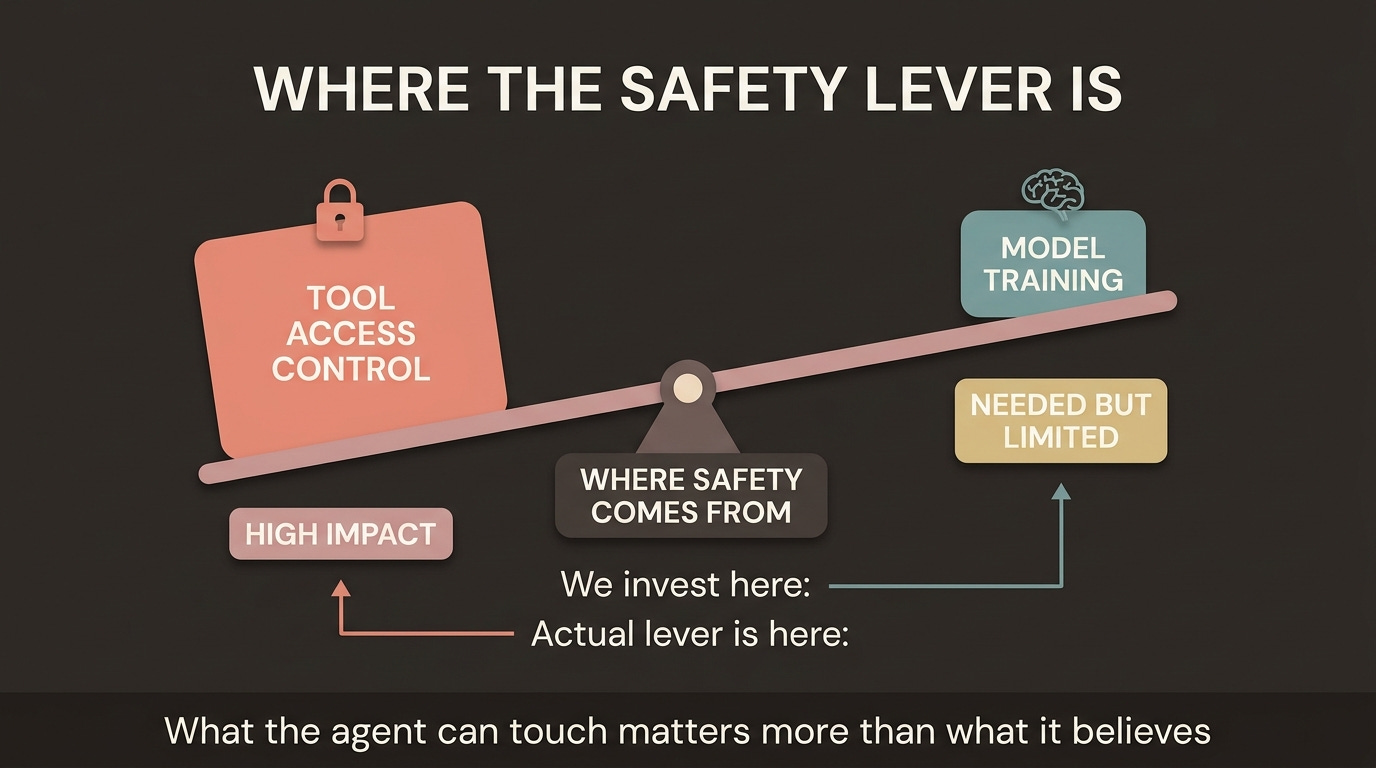
Here is the critical insight: how you prompt the model and what tools you give it is more determinative of behavior than the model’s underlying alignment. At the context engineering level, agent designers control behavior. This is not a flaw in current systems. It is the architecture. The agent designer has more leverage over outcomes than the model trainer.
This means aligning agents is the harder, more urgent problem - and it requires completely different mechanics than aligning models. Yet the research focus remains disproportionately on LLM-layer alignment.
Section 4: The Tool Chokepoint Thesis
If we accept that:
1. Perfect LLM alignment is mathematically impossible
2. Agent behavior is more controlled by tool access than model weights
3. Bad actors can always find workarounds through open-source models or jailbreaks
Then the question becomes: what is the actual safety lever?
The answer is tool access control - specifically, limiting what high-consequence systems agents can connect to regardless of who built the agent or how it is aligned.
Think about how we handle dangerous capabilities in the physical world. We do not try to prevent people from having malicious intent. We cannot. What we do is limit access to the materials that make malicious intent catastrophic. You can want to build a nuclear weapon. That want is harmless without access to enriched uranium. The safety architecture is at the capability layer, not the intent layer.
Gene synthesis companies already operate this way. You cannot order DNA sequences matching known pathogen signatures from major providers without triggering automatic screening and review. This is voluntary industry self-regulation at the capability provider level, coordinated through the International Gene Synthesis Consortium. It is imperfect - gaps exist - but it demonstrates that chokepoints at the capability provider layer are buildable and operational.
The question is whether we can build equivalent chokepoints for digital infrastructure before the window closes.
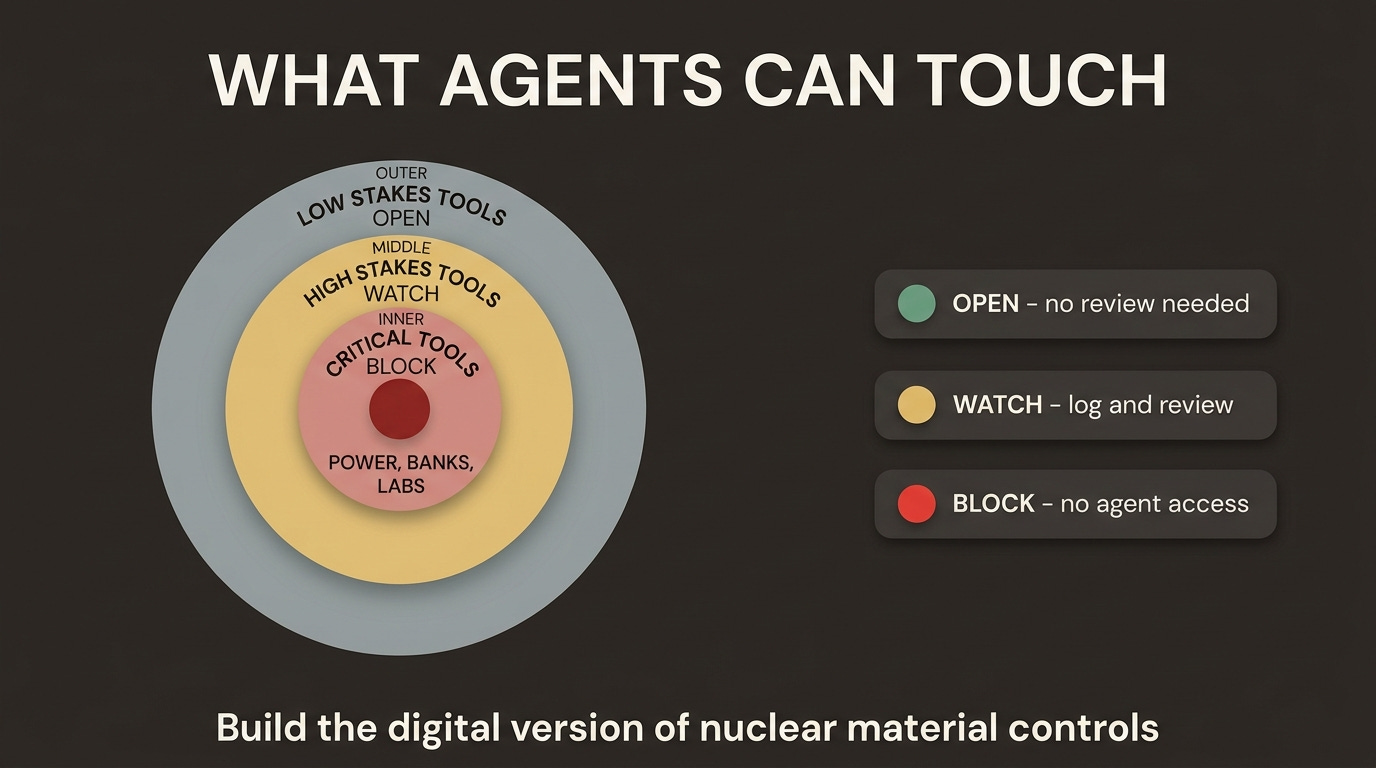
Here is what a tiered tool access framework might look like:
Tier 1 - Critical infrastructure (catastrophic damage potential)
● Power grid and SCADA systems
● Water treatment and distribution controls
● Core financial rails (central bank systems, settlement infrastructure)
● Nuclear and biological laboratory automation
These systems already have significant access controls. The question is whether those controls are designed with autonomous agent threat models in mind - because the attack surface for an agent with persistent goal-pursuit is fundamentally different from a human operator making a single authorized request.
Tier 2 - Severe impact (currently under-controlled)
● Hospital operational systems - drug dispensing, device control, surgical robotics
● Telecommunications routing infrastructure
● Large-scale cloud infrastructure management
● Aviation and logistics coordination systems
An agent with write access to hospital drug dispensing systems does not need to be misaligned to cause harm. It only needs to be pointed at that system by someone with bad intent. Current access controls were not designed for agentic threat models.
Tier 3 - High leverage, largely uncontrolled today
● Mass autonomous social engineering at scale (phone, email, synthetic media)
● Automated exploit generation and deployment pipelines
● Supply chain code injection at package repository scale
● Physical actuation through robotics and autonomous vehicles
This tier is where the window may already be closing. The tooling to automate sophisticated social engineering at scale exists today. The ability to generate and deploy novel exploits autonomously is not far off.
Section 5: The Individual Actor Problem
All of this converges on a structural reality about the world we are entering.
We are moving into an era of highly impactful individuals and small groups. A single person with domain expertise, an agentic system, and clear goals can now accomplish what previously required an organization. This is mostly good. It will also sometimes be catastrophic.
The current distribution of power in society is partly a function of the friction required to cause harm at scale. Building a bioweapon required a nation-state or a heavily resourced organization. Launching a sophisticated cyberattack required a well-resourced criminal organization or government intelligence agency. Executing complex financial fraud required teams of specialists. Agentic AI systematically reduces these friction costs.
We cannot prevent people from having bad intent. We have never been able to do that. What we have historically done is structure access to dangerous capabilities so that individual bad intent, on its own, is insufficient to cause civilizational harm.
Alignment research, however excellent, does not solve this problem. An aligned model that can be jailbroken, plus an abliterated open-source alternative, plus infinite agentic wrappers means that intent remains the real variable. The only levers we have left are:
4. Tool access registries - knowing what high-consequence systems agents are connecting to
5. Accountability chains - holding agent designers and operators responsible for what their systems do
6. Capability chokepoints - limiting access to the materials required for catastrophic harm, analogously to physical dangerous goods controls
The third lever is the most powerful and the least developed. We have barely started building it.
Section 6: What Comes Next
The alignment conversation is not wrong. It is incomplete.
Yes, we need better model alignment. Anthropic’s constitutional AI approach is serious research producing real improvements. The production-vs-academic divergence in safety research - where academic work targets attack success rates while production teams optimize for false positive rates and inference cost - is a real problem worth solving. Alignment faking, where models behave differently during evaluation than deployment, is a genuine threat that deserves continued attention.
But none of this changes the fundamental arithmetic: a determined bad actor with sufficient technical capability can get an AI system to help them with almost anything, either through frontier model manipulation or open-source alternatives. Even as frontier models improve at refusing direct requests, abliterated open-source variants remove those guardrails entirely - and the availability of capable base models continues to expand.
The safety architecture that will actually matter over the next decade is not primarily about what models believe. It is about what they can touch.
Building access control registries for high-consequence tool interfaces - the digital equivalent of nuclear material tracking - is the unsexy, technically complex, politically fraught work that the alignment conversation mostly ignores. It requires cooperation between infrastructure providers, regulatory frameworks that move faster than they currently do, and honest acknowledgment that we are past the point where any single organization’s alignment choices can be the primary safety guarantee.
We are betting civilization on institutional goodness. That bet needs a hedge.
Conclusion
The alignment debate in its current form asks: how do we make AI systems that want to do good? That is a real question worth answering. But it assumes that model intent is the primary variable determining outcomes.
In an agentic world, it is not.
The primary variable is what systems the agent can access and what the human who built it intends to accomplish. The model alignment layer is necessary but fundamentally insufficient - both because perfect alignment is provably undecidable and because the attack surface for extracting misaligned behavior from any capable model is effectively infinite.
The question we should be asking - urgently, now, before the window closes - is different: which tools are consequential enough that access to them should require the same kind of oversight we apply to enriched uranium, pathogen synthesis, and weapons-grade materials?
We know how to build chokepoints. We have done it in the physical world for decades. The gene synthesis industry already provides an imperfect but functional model at the intersection of biology and digital tooling.
The gap is not technical capability. It is urgency - and the willingness to acknowledge that alignment research, as important as it is, is solving a necessary but not sufficient piece of the problem.
References
[Anthropic Constitutional AI research](https://www.anthropic.com/research/constitutional-ai-harmlessness-from-ai-feedback)
[Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs](https://arxiv.org/abs/2502.17424)
[METR - Model Evaluation & Threat Research](https://metr.org)
[Gene synthesis screening - NTI Biosecurity](https://www.nti.org/analysis/articles/dna-synthesis-screening/)